 Romain Loiseau1,2
Romain Loiseau1,2 Baptiste Bouvier3
Baptiste Bouvier3 Yann Teytaut3
Yann Teytaut3 Elliot Vincent1,4
Elliot Vincent1,4 Mathieu Aubry1
Mathieu Aubry1 Loïc Landrieu2
Loïc Landrieu2Abstract¶
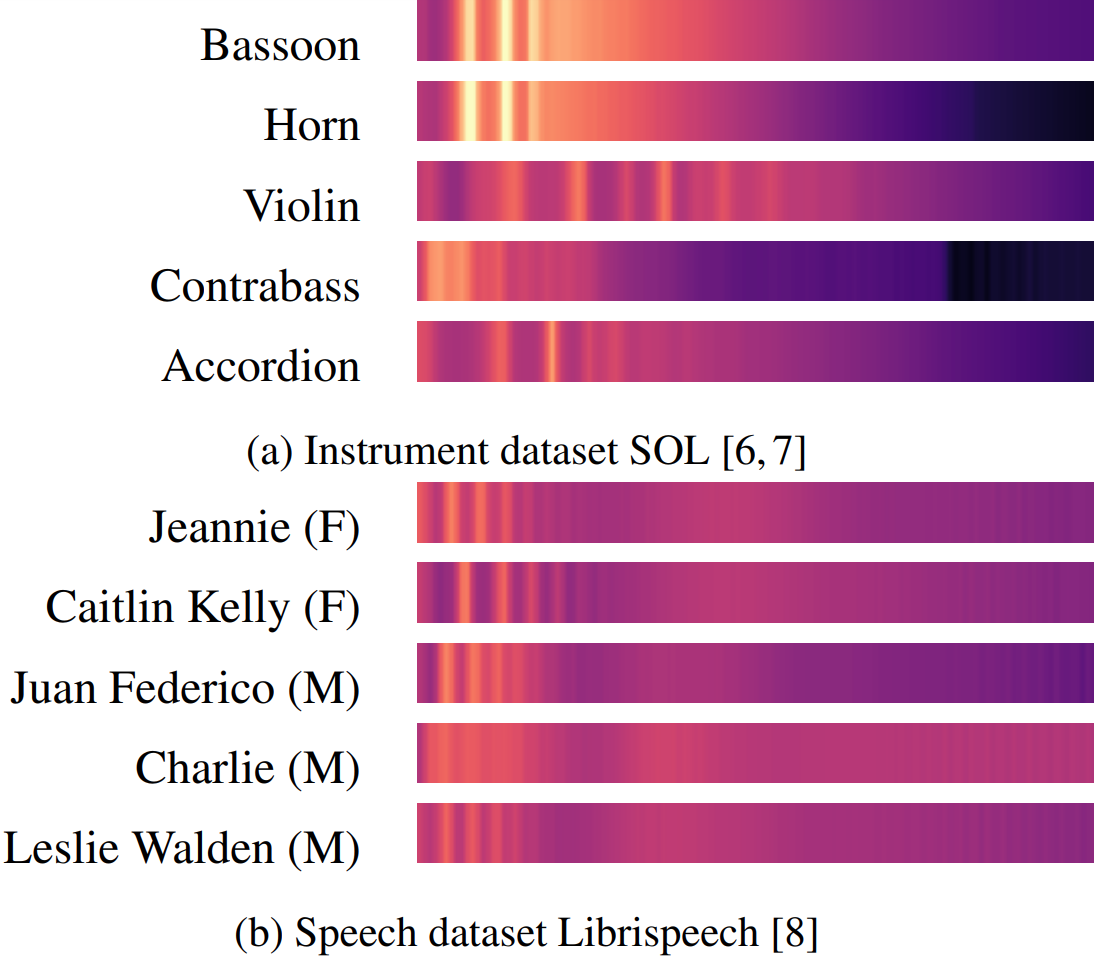
Machine learning techniques have proved useful for classifying and analyzing audio content. However, recent methods typically rely on abstract and high-dimensional representations that are difficult to interpret. Inspired by transformation-invariant approaches developed for image and 3D data, we propose an audio identification model based on learnable spectral prototypes. Equipped with dedicated transformation networks, these prototypes can be used to cluster and classify input audio samples from large collections of sounds. Our model can be trained with or without supervision and reaches state-of-the-art results for speaker and instrument identification, while remaining easily interpretable
Pipeline¶
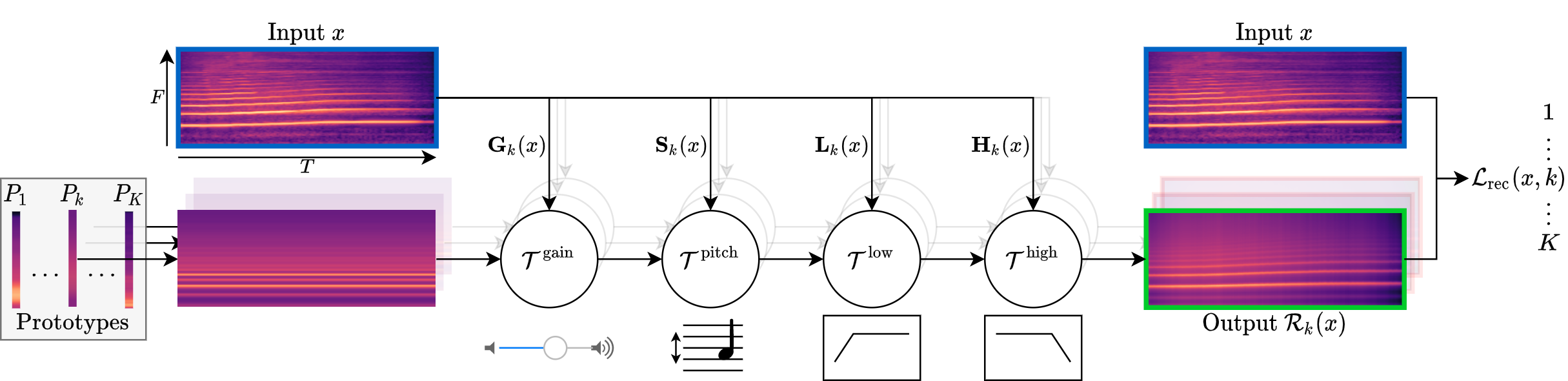
Ressources¶
If you find this project useful for your research, please cite:
@article{loiseau22amodelyoucanhear,
title = {A Model You Can Hear: Audio Identification with Playable Prototypes},
author = {Loiseau, Romain and Bouvier, Baptiste and Teytaut, Yann and Vincent, Elliot and Aubry, Mathieu and Landrieu, Loïc},
journal = {ISMIR},
year = {2022}
}Acknowledgements¶
This work was supported in part by ANR project Ready3D ANR-19-CE23-0007 and HPC resources from GENCI-IDRIS (Grant 2020-AD011012096).